- The Musings On AI
- Posts
- 🌻 E43: ML Deployment is a mess and Simplismart is solving it
🌻 E43: ML Deployment is a mess and Simplismart is solving it
Indian Startup Secures $7M in Funding to Enhance LLM Model Serving
Daksh Goel
November 07, 2024

Today’s post is a little distinct. It’s about how ML deployment is a headache for engineers at large enterprises and how Simplismart aims to solve it with the fastest inference engine, a Terraform-like orchestration, and a $7 Million Series A round from Accel.
If you plan to deploy models on-prem, book a demo with them:
🌸 Existing Deployment Approaches
🌼 The Naive Approach
Firstly, let’s start with how to deploy a Machine learning model. Here’s the code on the Huggingface transformers documentation:
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B"
pipeline = transformers.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto")
pipeline("Hey how are you doing today?")Problems with this approach: As soon as you try inferring at a scale of 10, 20, or 100 requests per second, your system will crash. This is primarily due to high GPU usage.
In production, inference speed and reliability are essential, and you can’t practically build something with a system that might crash due to high loads.
🌼 The Production Approach:
Several considerations and best practices should be implemented to produce the given code for working at scale.

From infrastructure to serving, you need to ensure everything is reliable.
🏵️ Infrastructure Considerations
Acquiring and allocating GPU virtual machines, especially NVIDIA H100s and A100s, is costly from infrastructure providers like AWS, Google Cloud, or Azure.

Obtaining the same bare metal directly from data centres and making it work is a headache. These data centres are slow, lack proper networking & come pre-installed with incompatible older software.
In addition, there is a sharp need to containerise ML models and dependencies using tools like Docker and Podman for consistent deployment across environments. Kubernetes is also needed to manage containerised deployments, enabling easy scaling, load balancing, and self-healing.
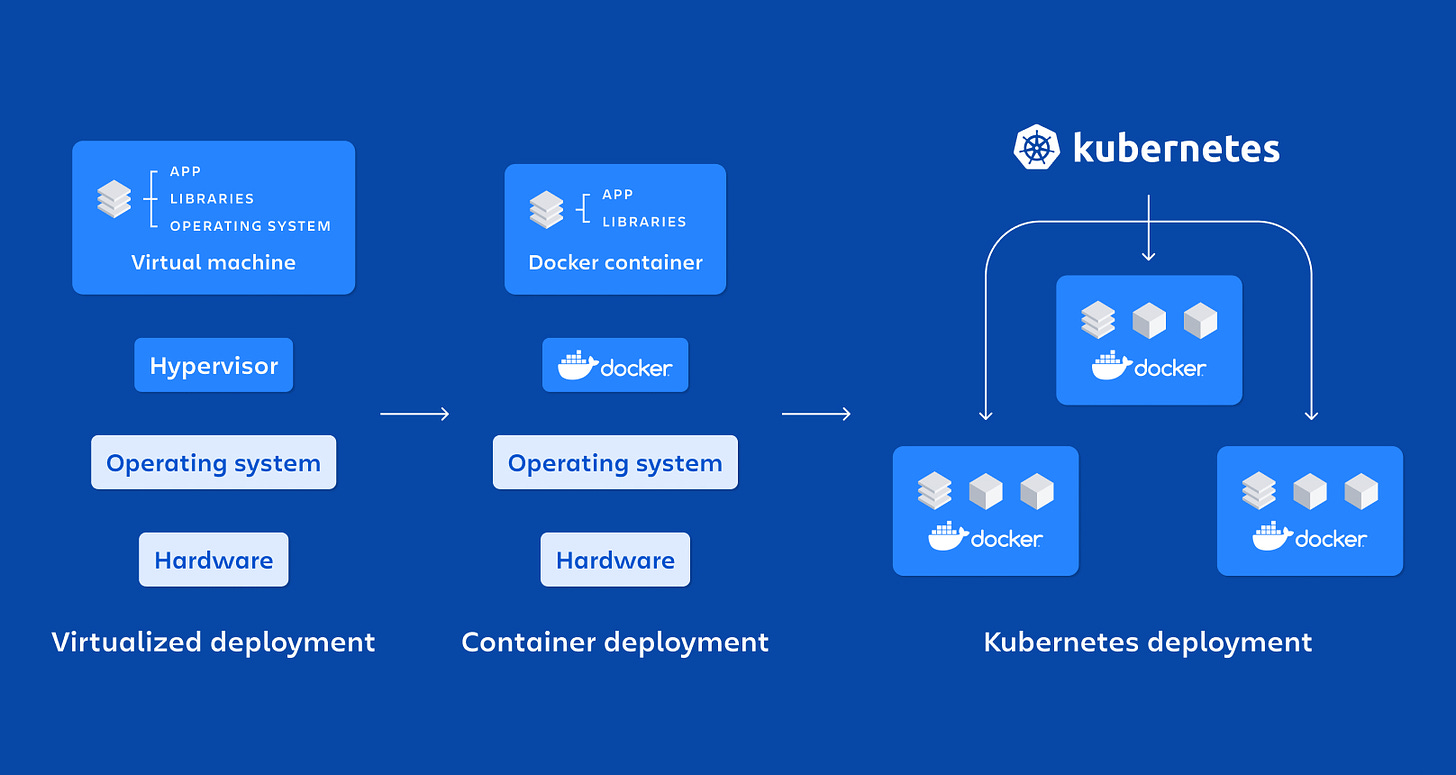
Docker and Kubernetes are necessary to enable deployment at scale
🏵️ Model Serving
Once the infrastructure is taken care of, a model-serving and inference engine layer that runs on top of the Docker-Kubernetes setup and creates a RESTful API is needed.
Due to speed constraints in use cases like voice bots, many workloads also need gRPC and WebSockets off the shelf. Finding the most efficient model backend, inference engine, and model serving layer for your needs requires a grid-search hell.
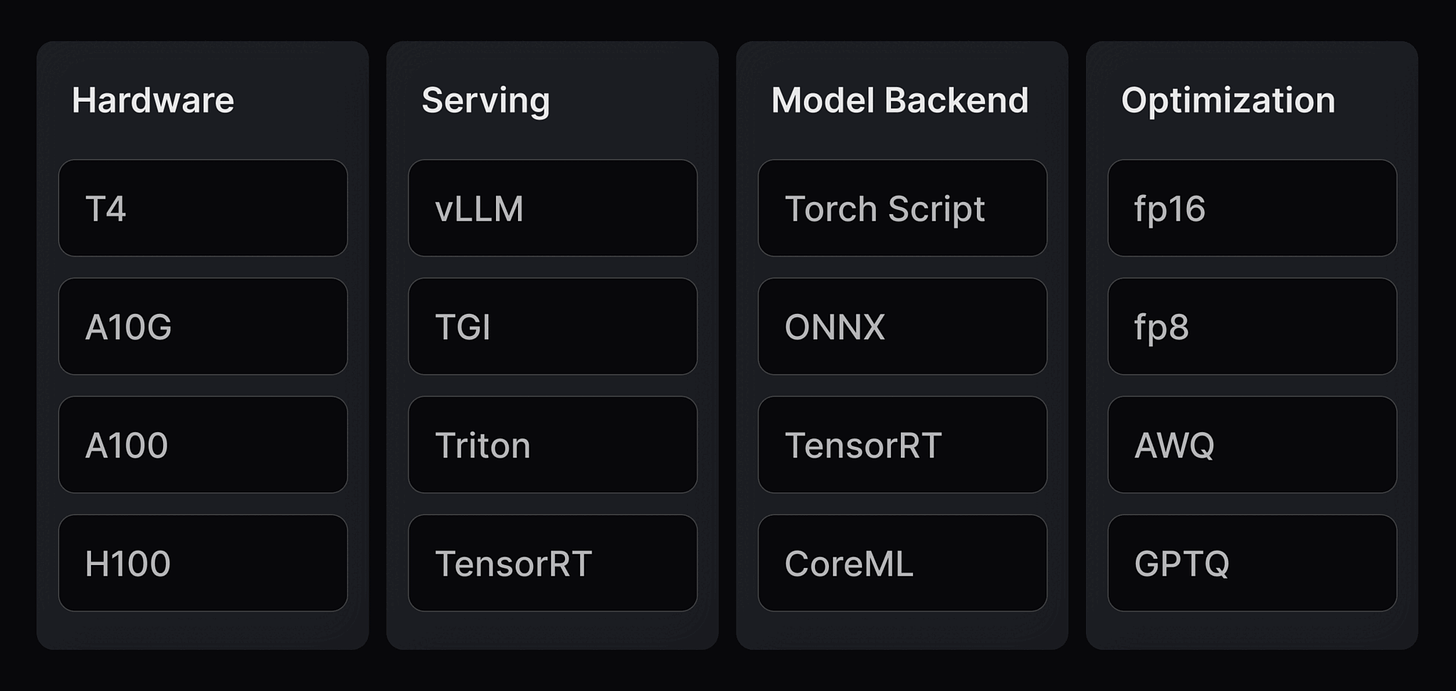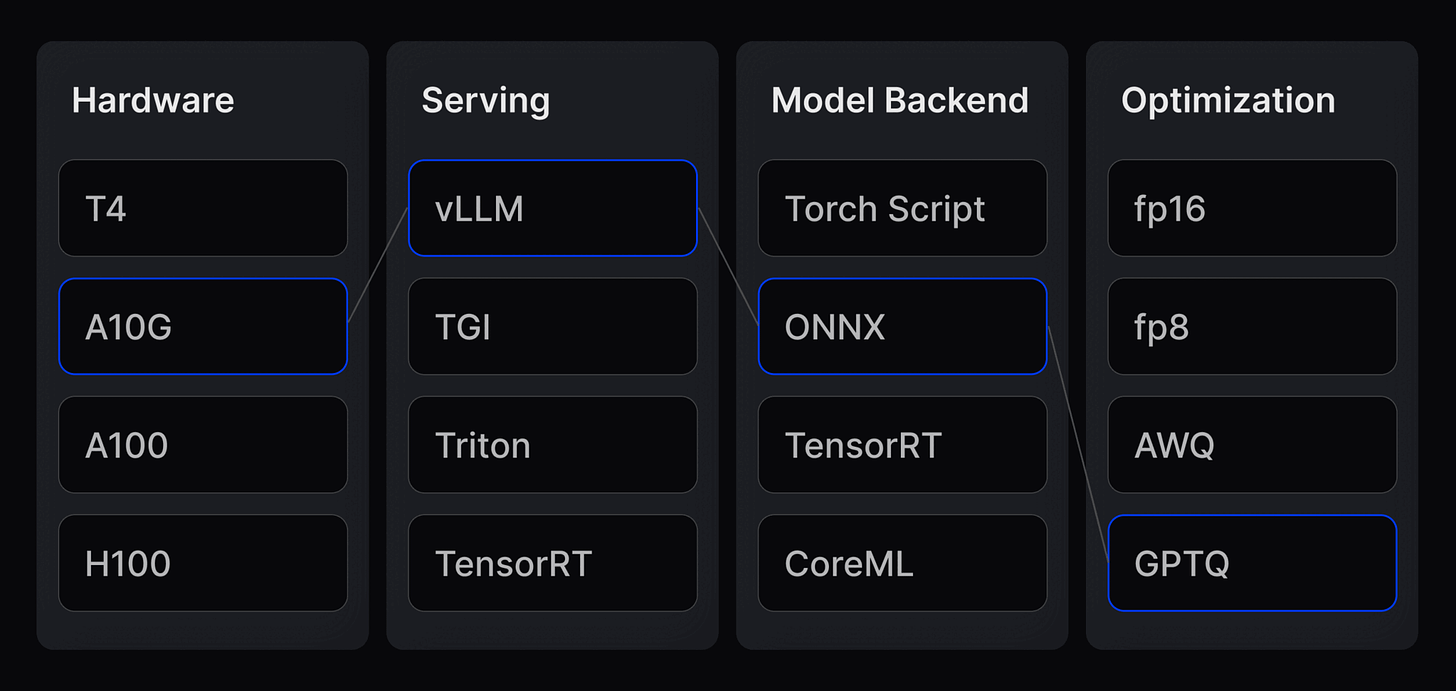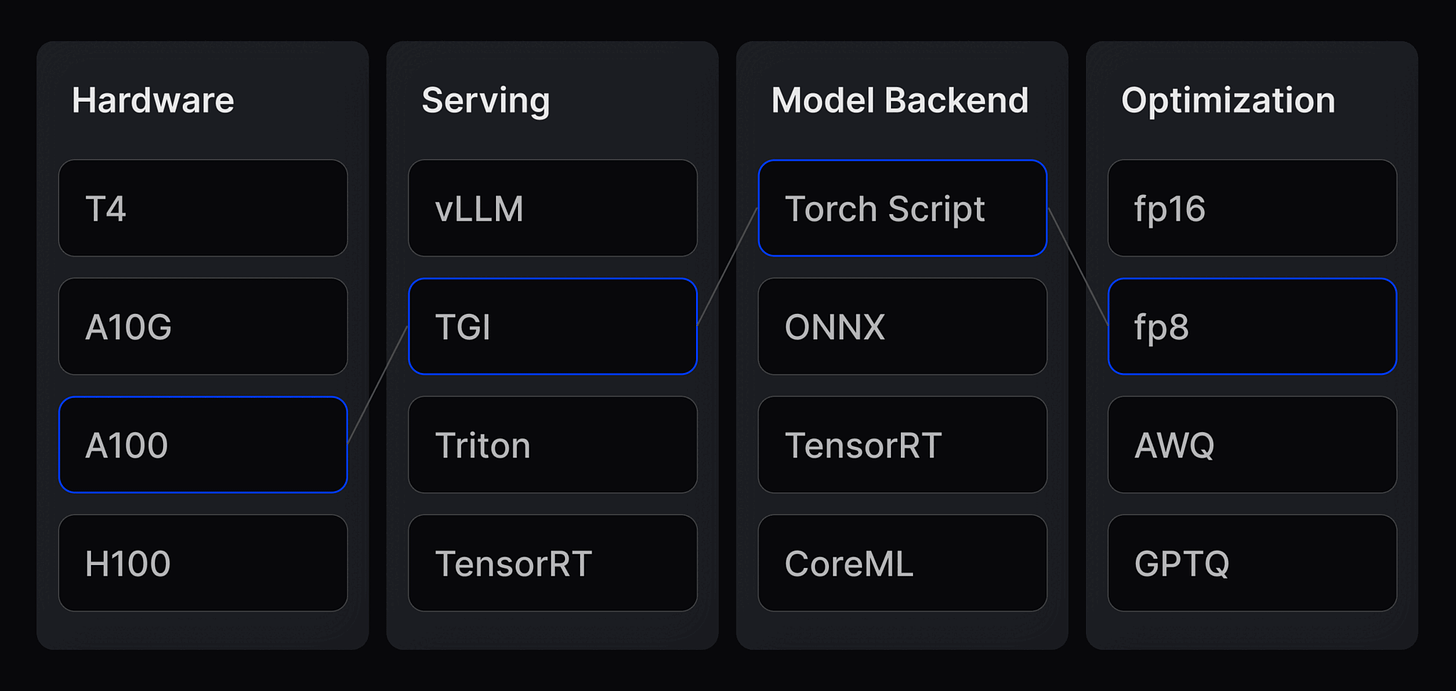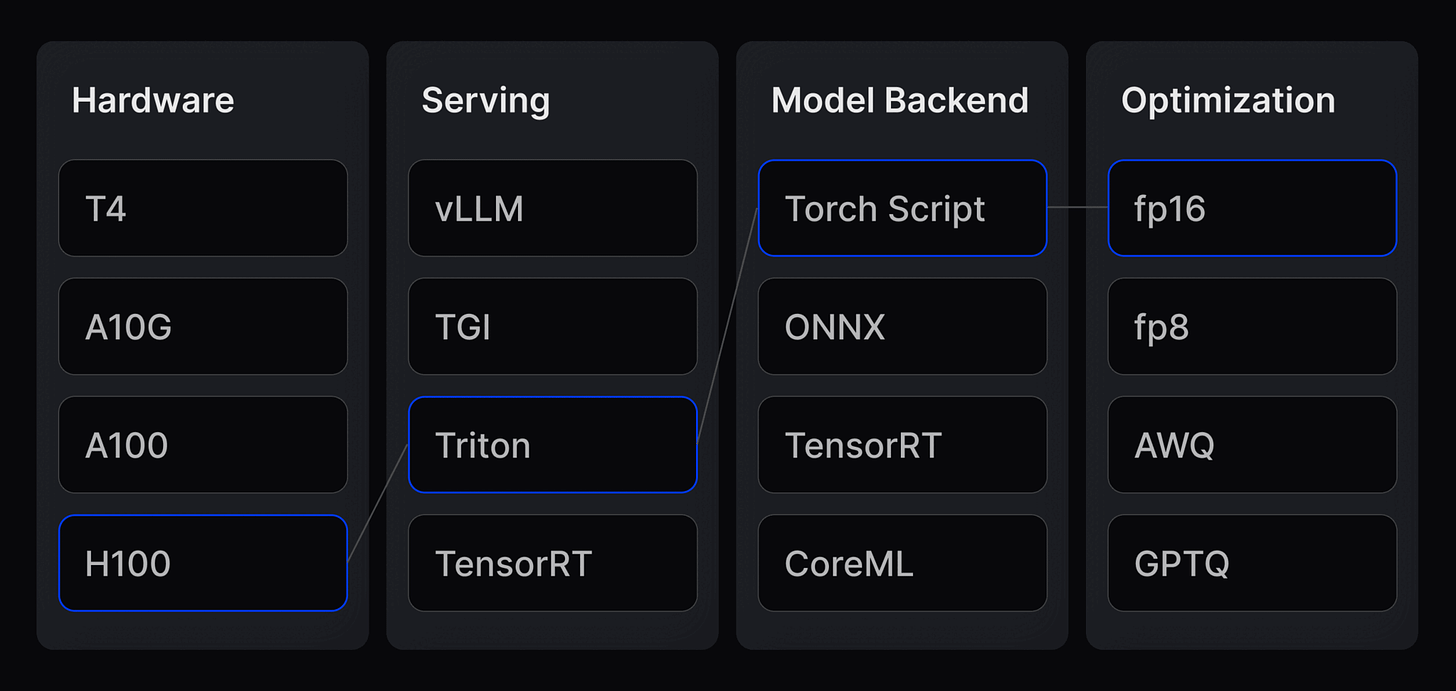
Finding the best hardware, serving layer and model backend with the perfect optimisation is super tricky.
Finding the perfect stack for scaling at the ideal speed requires matching the most efficient model backend (ONNX vs. CoreML vs. Torchscript) to the best serving layer (vLLM, Triton, TensorRT).
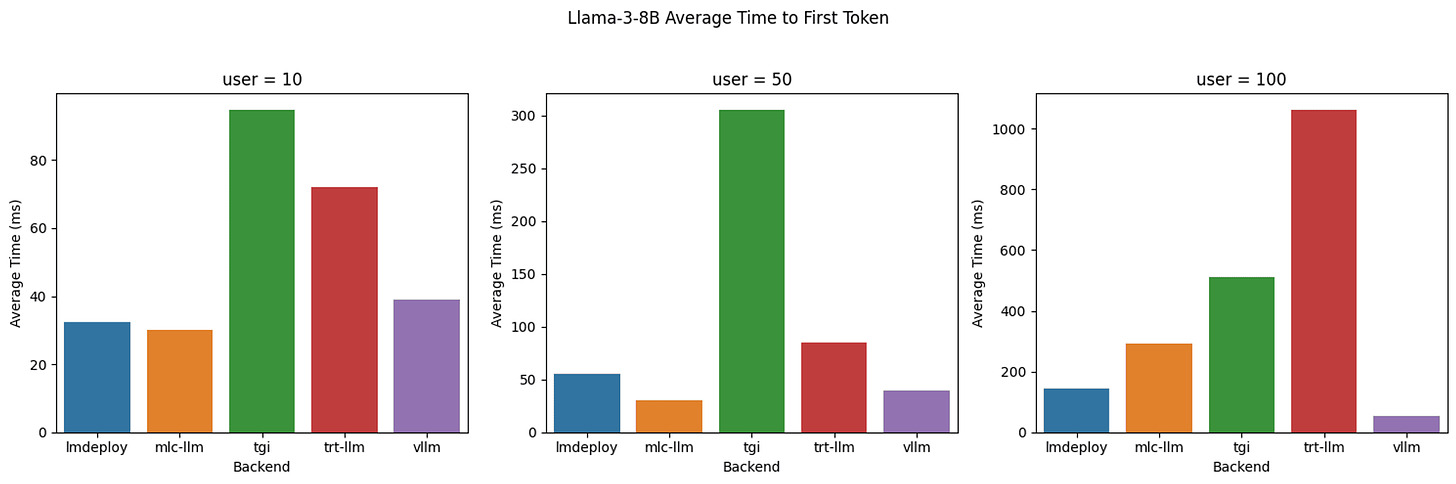
No model backend or serving layer is efficient across the board.
A dedicated model-serving solution is crucial for managing the complexities of inference in a production setting. Solutions like TensorFlow Serving, TorchServe, NVIDIA Triton Inference Server, or TensorRT LLM allow optimized model handling. These tools handle requests consistently, reducing latency and improving response time.
Once the infrastructure and model backend are looked after, MLOps engineers have to iterate the system until they get to the best latency vs throughput vs cost vs quality.
🌼 Optimisation Techniques Applied in LLM Deployment
Speed Optimizations:
For faster inference, there’s a need to reduce model precision through quantization (e.g., 32-bit to 8-bit).
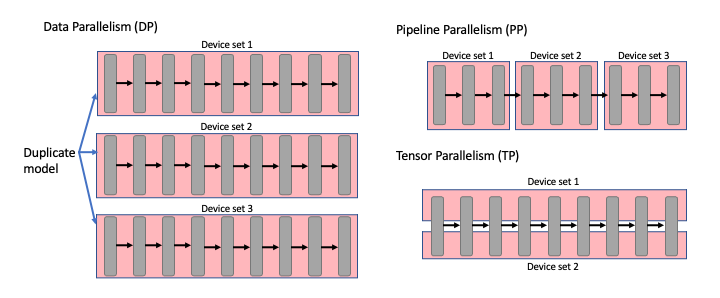
You need to deal with data parallelism and pipeline parallelism if they are to run heavy workloads on GPUs with limited RAM.
Attention mechanisms like Flash Attention, KV-Cache and Paged Attention.
Cost Optimization:
Serverless computing is needed for sporadic workloads.
Many companies prioritise async and batch processing for higher throughput when real-time responses aren't required.
Model Pruning is another way to save cost and decrease latency with minimal accuracy loss.
Rapid scaling is required to solve the overallocation and underallocation of GPUs.
Enterprises implement caching mechanisms for frequently requested inputs to reduce computation.

Quality Optimization:
Implementing ensemble modeling for better accuracy.
Finetune smaller models to reduce inference time, keeping model quality intact.
Monitoring and Maintenance:
After everything seems to fall into place—the infrastructure, the model serving, and the optimisations—and an enterprise is ready to serve production workloads, comprehensive logging and monitoring using tools like Prometheus andGrafana are needed.
These tools help track model performance and identify issues in real-time. Setting up a model registry to manage different versions of the model and implementing A/B testing capabilities is equally important.
Simplismart is Abstracting Everything
🌼 What is Simplismart?
Simplismart is an end-to-end MLOps platform for Generative AI workloads. It helps make fine-tuning, deploying, and observing models effortlessly. In addition, it has the fastest inference engine globally and abstracts the whole process to solve the grid-search hell problem.

🌼 Their Funding Round
Simplismart just raised $7 million in a Series A round led by Accel. You can read more about it here. The founding team includes infrastructure and machine learning engineers from Google Search, Oracle Cloud, AWS, and Uber.

On top of this, Simplismart is also the fastest infrastructure platform for Generative AI workloads. They have lightning-fast speeds:
330+ tokens/ sec. with Llama3.1-8B
225x real-time factor with Whisper-Large-v3
<0.7 seconds to generate an image with SD-XL
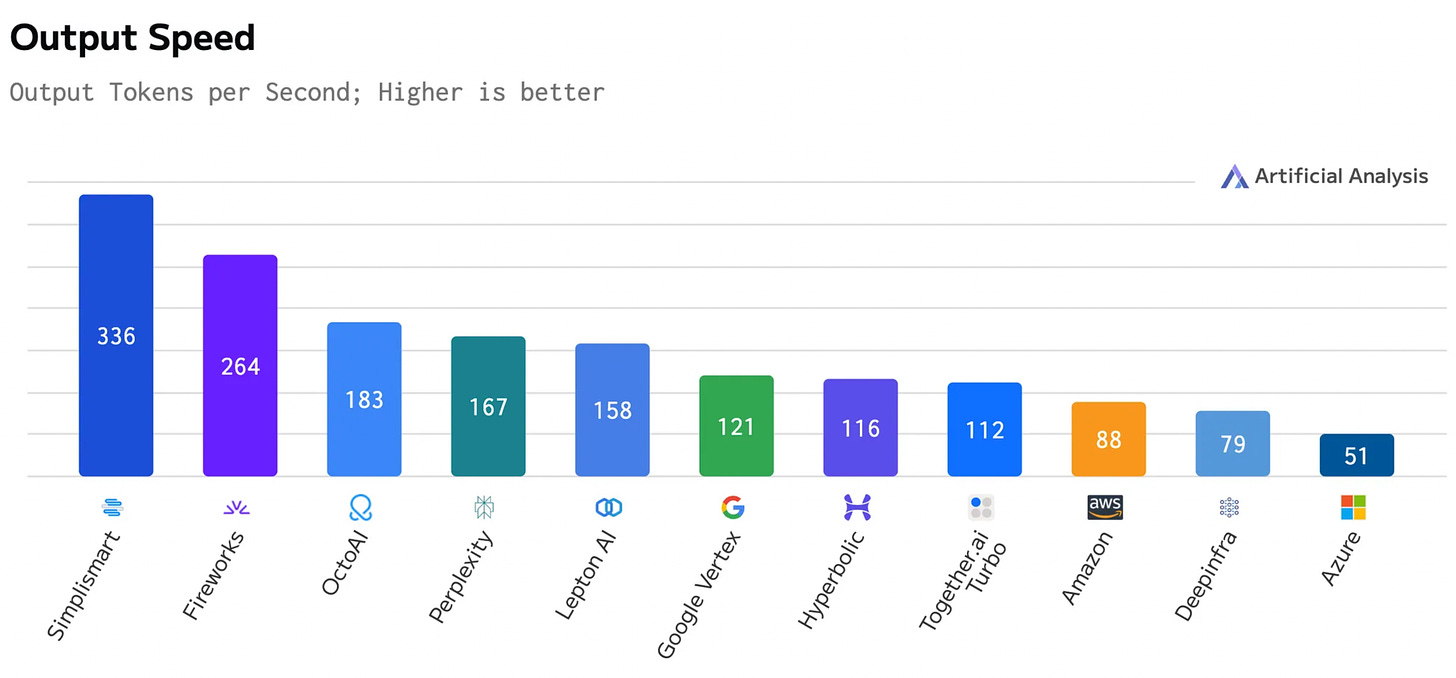
Simplismart gives up to 336 tokens/ sec. on Llama3.1-8B, making them the fastest inference engine for artificial analysis.
They have already optimised deployments for 30+ enterprises, saving their clients more than 4 million dollars. Do schedule a call with the team to explore how they might help you.

🌸Choice Cuts
🌼 New York Times reporters used AI tools, particularly LLMs, to transcribe and analyze over 400 hours of audio for an investigation.

🌼 Will we now move towards freedom over the AI systems that will educate our next generation and embrace the true values of a liberal democracy?

🌼 Lagrange multipliers are a go-to tool for anyone who’s worked in optimization. And I found a clear visual representation of it.

🌼 A curated list of Large Language Model resources, covering model training, serving, fine-tuning, and building LLM applications.
🌼 Ever spend weeks building an AI system, only to realize you have no idea if it’s actually working? You’re not alone. I found a beautiful blog on that.
🌸 Podcasts
There’s a lot more I could write about but I figure very few people will read this far anyways. If you did, you’re amazing and I appreciate you!
Love MusingsOnAI? Tell your friends!
If your company is interested in reaching an audience of AI professionals and decision-makers, reach us.
If you have any comments or feedback, just respond to this email!
Thanks for reading, Let’s explore the world together!
Raahul
Reply